
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | |
| 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 14 | 15 | 16 | 17 | 18 | 19 | 20 |
| 21 | 22 | 23 | 24 | 25 | 26 | 27 |
| 28 | 29 | 30 | 31 |
- 자바
- java의 작동방식
- column
- coding language
- database
- 조건식 여러개
- 언어알기
- db
- 간단한 검색
- TIL
- 랜덤 닉네임 생성기
- Table
- where 조건식
- mysql
- java알기
- java가 중요한 이유
- left()
- 자바트랙
- right()
- 스프링 트랙
- java
- import.java.util.random
- like %
- sql
- 리스트자료형
- 대문자 자동변환
- 데이터베이스
- dbms
- dbeaver
- sql 사칙연산
- Today
- Total
수수한 코딩세상
[DB] 데이터베이스의 종류 본문
데이터의 중요성
우리들의 일상 속에서 데이터는 지금 이 순간에도 생성되어 저장되고 있습니다.
지금 우리가 사는 세상에서 데이터가 중요한 이유는 데이터를 가공해서 다양한 일을 할 수 있기 때문입니다.
인터넷에 연결된 웹과 앱을 통해 소식과 지식을 전달하거나, 대규모의 데이터로부터 통찰력 있는 분석결과를 뽑아낼 수도 있습니다.
이런 일을 하기 위해서는 데이터를 다룰 수 있어야 합니다.
데이터를 저장하는 방법으로 제일 간단한 방법은 파일(File)에 저장하는 것입니다. 하지만 한글문서와 워드 같은 파일은 만능이 아닙니다. 성능, 보안, 편의성, 검색 등에 한계가 있습니다.
이러한 파일의 한계를 보안해서 나온 소프트웨어가 바로 Database입니다.
Database를 이용하면 소중한 데이터를 안전하고 편리하게 이용하고 보관할 수 있습니다.
Database에는 MySQL, Oracle, MongoDB 등과 같은 다양한 데이터베이스 제품들이 있습니다.
데이터베이스의 종류
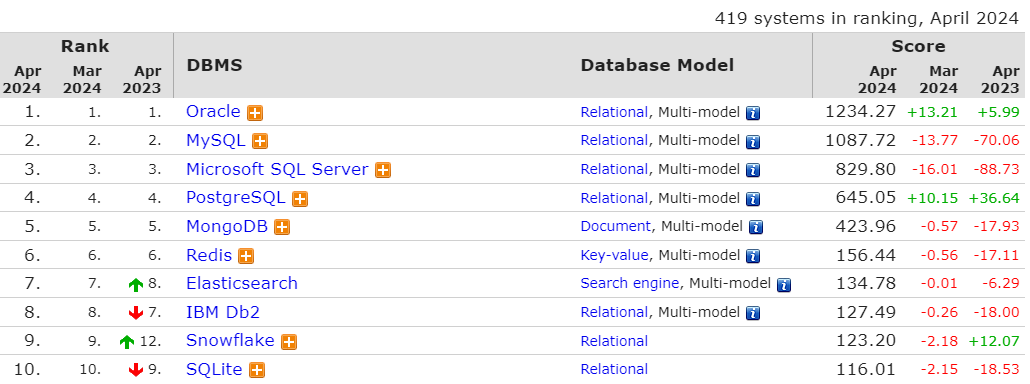
데이터베이스에는 다양한 제품들과 제품마다의 종류들이 있습니다. 제일 많이 사용하는 제품의 데이터베이스 종류는 Relational Database로 관계형 데이터베이스들이 많습니다. 그 외에도 Document Database, Key-Value Database 등이 있습니다. 이번 글에서는 이러한 데이터 베이스의 종류에 대해 간단하게 정리해보고자 합니다.
더 자세한 내용들은 좀 더 공부해 나간 후 정리해 보도록 하겠습니다.
매달 데이터베이스 관리 시스템의 순위를 매겨 데이터베이스 순위를 알아볼 수 있는 사이트 링크를 아래에 첨부합니다.
https://db-engines.com/en/ranking
DB-Engines Ranking
Popularity ranking of database management systems.
db-engines.com
Key-Value Database
NoSQL(비정형) 데이터베이스의 대표적인 데이터베이스로 Key-Value Database가 있습니다. Key는 레코드를 고유하게 식별할 수 있는 데이터로 저장과 검색하는데 사용됩니다. Value는 다양한 형의 데이터를 저장할 수 있습니다.
키와 값으로 이루어진 데이터베이스로 데이터를 저장하고 조회하는 가장 간단한 기능에 충실한 데이터베이스입니다.
데이터를 조회하는데 특화되었다 보니 메인 DB로 사용하기 보다는 서브용도로 많이 사용하는 데이터베이스입니다.
Key-Value Database 중에서 대표적인 제품이 레디스(Redis) 입니다.

Redis가 대표적인 이유는 데이터를 하드디스크에 저장하지 않고 램에 저장하는 방식의 저장소이기 때문입니다. 하드디스크에는 데이터를 백업해 두고, 실질적인 데이터는 램에 저장하여 연산하기 때문에 빠른 데이터 조회가 가능합니다.
하지만 메인 Database로 사용하기에는 부족하여 보통 메인 Database를 따로 두고, 자주 사용하는 데이터를 Redis에 저장해 두어 사용하는 Database 구조로 활용할 때 많이 사용합니다.
그 외에도 자주 쓰는 데이터 캐싱, 채팅을 위한 pub/sub 패턴, 영상스트리밍, 로그인기록 저장 등에 사용합니다.
pub/sub 패턴
Publisher-Subscriber Patter의 줄임말로 직역하면 발행-구독 패턴입니다.
발행-구독 패턴은 비동기 방식의 메시징으로 발행자와 구독자가 있고 그 사이에 메시지 큐(=Event Channel)가 존재하는 형태입니다. 발행자(Publisher)는 구독자(Subscriber)를 모른 채로 이벤트를 발생시켜 Event Channel에 메시지를 넘겨주고 Event Channel이 메시지를 전달하는 방식이라고 보면 됩니다.
Relational Database
관계형 데이터 베이스는 제일 대표적인 Database라고 할 수 있습니다. 위의 데이터베이스 관리 시스템 순위표에서 봤다시피 상위권 데이터베이스들은 모두 관계형 데이터 베이스임을 알 수 있습니다.
관계형 데이터 베이스는 기본적으로 표를 만들고 그 표에 데이터를 저장합니다.

관계형 데이터베이스의 자세한 내용은 다른 페이지로 정리해 올리도록 하겠습니다. 지금은 가볍게 봐주시길 바랍니다.
- 관계형 데이터 베이스를 사용할 때는 SQL(Structured Query Language)라는 언어를 사용합니다.
- 관계형 데이터 베이스는 데이터 중복을 싫어해서 보통 데이터를 정규화해서 저장합니다. 정규화란 중복된 데이터를 다른 테이블로 빼서 중복을 제거하는 과정을 이야기합니다. 정규화의 단점은 한 데이터에 대하여 여러 테이블에 저장하다 보니 출력문의 문법이 복잡해지는 것입니다.
- 관계형 데이터 베이스는 트랜젝션 기능이 있어 작업실패 시 롤백이 가능합니다. 이러한 기능을 ACID Transaction 기능이라고 합니다
Transaction
트랜젝션(Transaction)이란 여러 작업 들을 하나로 묶는 단위입니다. 묶은 한 덩어리의 작업들을 모두 실행하거나 모두 실행되지 않도록 하는 특징이 있습니다.
이러한 트랜젝션이라느 묶음이 필요한 이유를 은행작업에 비유해 설명하자면 A계좌에서 B계좌로 돈을 보낸다고 가정했을 때, A계좌에서 돈이 출금되고 나서 B계좌로 송금하려는데 갑자기 시스템이 멈추게 되면 출금된 돈이 송금되지 않고 없어지는 상황이 발생할 수 있습니다. 이러한 상황을 방지할 수 있는 보안책이 트랜젝션입니다. 돈이 출금되고 송금되어 완료되는 이 모든 과정을 트랜젝션으로 묶으면 중간에 시스템 에러가 나서 작동이 멈추어도 실행한 것 자체를 롤백시켜 데이터의 유효성을 보장해 줍니다.
ACID
ACID는 데이터의 유효성을 보장하기 위한 트랜젝션의 특징들의 앞글자를 딴 단어입니다.
- Atomicity (원자성) : 묶은 트랜젝션을 모두 실행하거나 아니면 모두 실행하지 않는(롤백) 것입니다.
- Consistency (일관성) : 데이터형에 맞게 데이터를 저장하거나 수정하는 규칙을 의미합니다. (예를 들어 숫자 속성에는 문자열데이터가 저장되지 않도록 하는 것입니다)
- Isolation (고립성) : 두 개의 트랜젝션이 실행되고 있을 때, 다른 한 트랜젝션의 작업들이 다른 트랜젝션에게 보이는 정도를 말합니다.
- Durability (영구성) : 데이터가 손실되지 않을 안전한 저장소에 저장되어 제공되는 것을 의미합니다. 한번 적용된 트랜젝션의 내용은 영원히 적용되어야 합니다.
트랜젝션과 ACID에 대해서 더 자세한 내용은 공부하여 다른 글로 찾아뵙겠습니다.
관계형 데이터베이스는 주로 입출력 속도보다 정확도가 매우 중요한 서비스에 사용합니다.
여담으로 관계형 데이터베이스의 relational의 relation은 행렬 배울 때 쓰이는 relation에서 따온 것이라고 합니다.
Graph Database
Graph Database는 NoSQL(비정형) 데이터베이스로 데이터 간의 관계를 데이터만큼이나 중요하게 생각하여 만들어진 데이터 베이스입니다.
흔히 우리가 아는 관계형 데이터베이스(Relational Database)도 관계를 어느 정도 나타내고 있지만 관계를 중점적으로 다루기에는 어려움이 있어 데이터 간의 관계를 중요하게 저장해야 할 때에는 Graph Database를 사용합니다.
데이터 간의 관계가 중요하다 보니 노드와 에지를 이용하여 데이터를 표현하고 저장합니다. 노드에는 데이터를 저장하고 노드와 노드 사이의 에지에는 관계를 나타내어 연결하는 데이터 베이스로 비행기 노선, SNS친구관계, 코로나 전염맵 등을 나타낼 때 사용합니다.
그리고 Graph Database는 Graph Query Language를 사용하여 개발하고 관리합니다.
Document Database
NoSQL(비정형) 데이터베이스로 관계형 데이터베이스보다 형식이 자유로운 데이터베이스입니다. 데이터베이스의 이름 그대로 문서형태로 데이터를 저장하고 관리합니다. 대표적인 Document Database로는 MongoDB, CouchDB, Clud Firestore 가 있습니다.
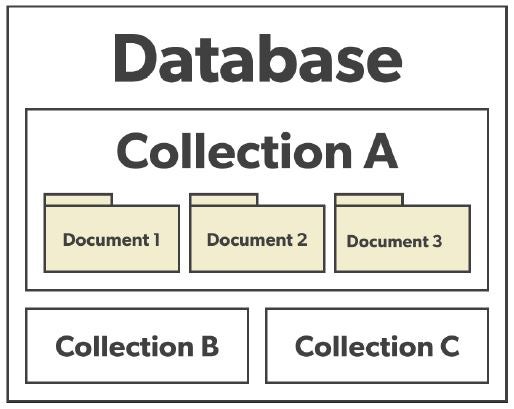
Document Database 구조는 Collection이라는 폴더를 안에 Document라고 부르는 파일을 만들고 그 파일 안에 JSON, XML과 같은 문서형태의 데이터를 저장하여 관리하는 구조입니다.
데이터의 중복제거인 정규화 없이 사용할 수 있습니다. Document Database는 데이터 분산을 염두하고 만든 데이터베이스여서 분산처리를 매우 잘해줍니다. 분산처리 시스템이 잘 되어 있어서 데이터의 일관성(정확도)은 떨어질 수 있습니다.
Column-family Database
NoSQL(비정형) 데이터베이스로 행(row) 대신 열(column)에 데이터를 저장하는 비관계형 데이터베이스입니다. 대표적인 예로는 Cassandra, Google Cloud Bigtable이 있습니다.
Column-family Database는 제품별로 자사가 만든 언어를 사용해야 합니다. 예를 들어 Cassandra는 Cassandra Query Language를 사용해야 데이터를 저장하고 관리할 수 있습니다. (SQL과 큰 차이는 없음)
테이블을 만들고 행(row)을 만들고 그 안에 자유롭게 열(column)을 만들어서 자료를 저장하면 됩니다.
정규화 없이 사용하기 때문에 데이터 입출력이 쉽고, 복제, 분산처리를 잘합니다. 하지만 분산처리를 하여 데이터 일관성 부족해집니다.
Search engine
일반적인 데이터 베이스로도 사용가능하지만 주로 메인 데이터 베이스의 서브 데이터 베이스로 많이 사용합니다. Search engine은 데이터를 인덱스에 보관하여 사용함으로써 빠른 검색을 도와줍니다. index는 빠른 검색을 도와주는 목차 같은 것이라고 생각하면 됩니다.
대표적인 Search engine으로는 Elastic, Amazon CloudSearch, Google Cloud Search가 있습니다.
기존 Database에서 데이터를 뽑아서 입력하면 index를 생성하고 보관해 줍니다. 검색요청이 들어오면 index를 통해 자료를 빠르게 검색하도록 도와주기 때문에 실시간 검색어, 추천 검색어, 검색어 오타교정 등의 부가적인 서비스를 쉽게 만들 수 있도록 도와줍니다. 주로 검색이 중요한 사이트를 만들 때 사용합니다.
참고한 자료 & 추천 영상
https://www.youtube.com/watch?v=ZVuHZ2Fjkl4
글을 읽기 귀찮고 시간이 없으신 분들 또는 간단한 설명이 필요하신 분들께는 코딩애플님의 "개발 시 데이터베이스 선택 가이드(총정리)" 영상을 추천드립니다!
이상 대표적인 데이터베이스의 종류에 대해서 정리해 보았습니다.
일반적 데이터베이스는 관계형이랑 도큐먼트를 많이 사용하기 때문에 둘 중에서 개발 서비스에 맞는 데이터베이스를 골라 사용하시면 좋을 것 같습니다.
정확도가 중요하지 않고 입출력이 많은 경우 Document Database를 추천드리고, 정확도와 일관성이 중요하시면 Relational Database를 사용하시는 것을 추천드립니다.
'수수한 코딩세상 > DB' 카테고리의 다른 글
| [DB] SQL SELECT / ORDER BY 문법 (0) | 2024.05.24 |
|---|---|
| [DB] MySQL 데이터 타입 (0) | 2024.04.24 |
| [DBeaver] DBeaver로 MySQL 테이블 만들기 (0) | 2024.04.16 |
| [DB] 데이터베이스의 본질 Create, Read, Update, Delete (CRUD) (0) | 2024.04.12 |
| [DB] DBMS 란 (0) | 2024.04.11 |



